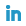



By Aimee Raleigh, Principal at Atlas Venture, as part of the From The Trenches feature of LifeSciVC
Drug discovery and development is a long, and often fraught, journey – it typically takes more than a decade to progress from idea to approved drug, and less than 10% of drugs that enter the clinic succeed in achieving commercialization. Creating new drugs for patients is certainly not for the faint of heart. Behind every story of a drug approved there are countless tales of challenges, whether it was early technology that failed to scale, early compounds that proved toxic in IND-enabling studies, lack of clinical efficacy that wasn’t predicted by preclinical models, and many more. The road to success is never straightforward and often takes many years to establish traction. As an industry we must be steadfast even in the face of extreme doubt or hardship. This is part of what makes us great.
However, there are times when refusing to stop and re-evaluate is to our disadvantage, especially if our (and our teams’) bandwidth can be better spent pursuing other potential therapies. I realize this moment in time is especially jarring to be discussing failure, when so many of our core institutions for novel thesis generation (NIH), drug development and approval (FDA), and the basic tenets of our biotech economy are in flux. But I believe the lessons on “failing fast” apply in any circumstance, and now more than ever are crucial as we think about ensuring enduring success for our ecosystem.
How do we define failure and success? How can we prospectively set up frameworks for decision-making to keep us honest when multiple experiments read out with gray or negative data? When do we collectively decide to shut down a program? Every team goes through periods of doubt, and the decision of when to stop and when to persevere is unique to each circumstance. That said, there are learnings we can draw from cumulative wisdom. For today’s post I am honored to have collected feedback from colleagues who have encountered the question of “should we stop” before, and have handled it with integrity and thoughtfulness:
- Alex Harding has previously written about the decision to stop, whether in shutting down seed-stage newco Apneo Therapeutics (here) or more generally as it applies to the public markets (here)
- Sam Truex spoke about the decision to shut down Quench Therapeutics after failing to identify tractable chemical matter against gasdermin D (here)
- Abbas Kazimi has written about “failing fast” when it comes to pipeline program management at Nimbus Therapeutics (here, here)
Whether during an exploratory newco build, after a large Series A financing, or for individual programs within a company’s pipeline, there are a set of frameworks that can help teams parse through difficult decisions. While we won’t be diving into any company-specific examples in this piece, I will share cumulative learnings and recommendations from Alex, Sam, and Abbas (and myself!) for how to approach decision-making in situations where the path forward is muddied.
Set up expectations before kicking off a new company or program
Failure is inherently defined as the inverse of success, but so often we don’t take the time to put pen to paper on what success looks like for an individual program or company. It’s essential to establish a rigorous evaluation mindset early in new company builds, and to continuously apply that mindset as objectively as possible. It takes time and thought, but before any amount of money is invested in a new idea, consider mapping out the program(s) in detail, including the first 1-3 indications with highest mechanistic rationale. In building the target product profile (TPP) for these, consider what makes the mechanism uniquely suited to address unmet needs in a given disease, and objectively map out what would be base, low, and high cases for the program in the context of the competitive landscape (see Fig. 1 for an exemplary framework).
As it’s often hard to dive headfirst into complexity, Sam recommends starting with the extreme cases – what does a mediocre or poor profile look like in this indication, and how does that compare to a stellar profile? From there, you can figure out the achievable but still differentiated middle ground, the “base case.” Once the theoretical profiles are established, you can then cross-check internal and external data over time to ensure the base case remains competitive and valuable. Make sure to always stay conscientious of changing relative benchmarks, as you wouldn’t want to put your head down in discovery for 5 years only to realize the landscape for your prioritized indication has completely changed and the bar is much higher than you originally thought. It’s important to maintain discipline over conviction when evaluating your programs against competitors – maybe you can justify moving forward with a program that hits the low vs. base case on one parameter, but for all others the program should meet or exceed the base case. To remain objective, it’s helpful to consistently pressure-test your view of the attractiveness of your program not only with insiders (team, board, investors), but also with external perspectives (e.g., key opinion leaders).
This logic is a little more straightforward for asset-centric companies, but what if you are developing an early discovery-stage platform? Similarly, it’s encouraged to map out your key 1-3 programs before even running any experiments to validate your platform. In the base case scenario, how can your new technology / modality uniquely enable the treatment of a disease beyond available (commercial and pipeline) therapies today? If you are at a loss for what these differentiated programs should be, it’s probably a sign that the platform concept needs some additional thinking before spending substantial funds to build it out.
Finally, perhaps an obvious point but one that goes unaddressed in many new companies: no one should be more familiar with “bear case” for your program than you. It’s a strength and not a weakness to fully understand the theoretical risks of the mechanism or modality in the context of your lead indication. In fact, it’s safe to assume that you will gain credibility in being aware of the risks and expounding upon (and refuting) them soundly.
Map out potential outcomes before an experimental readout
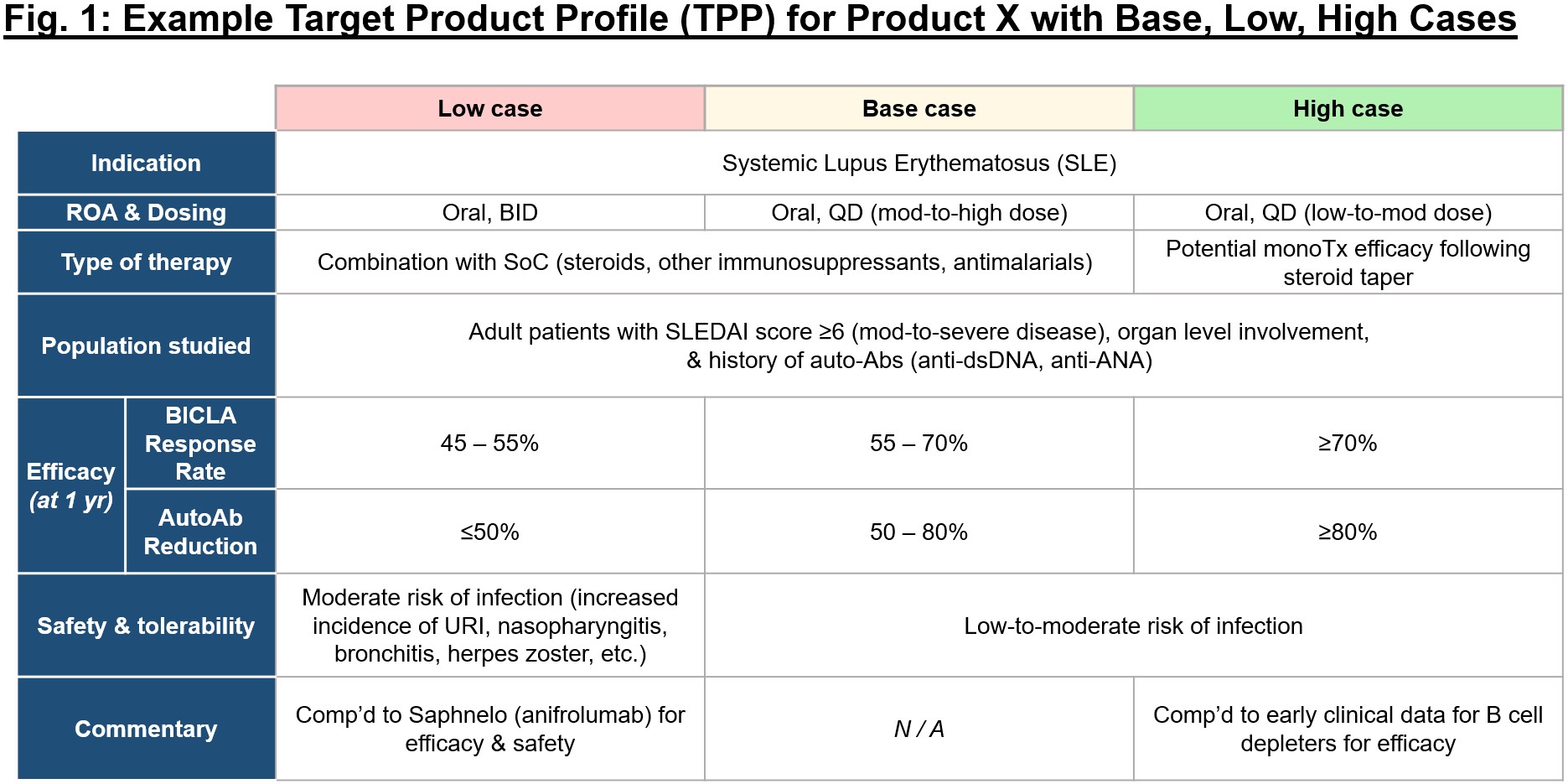
Of course, the initial theoretical TPP will change over time as you generate data and as the competitive landscape shifts, but it’s important to hold yourself accountable to “what good looks like” as a program progresses. It’s also useful when starting a program in discovery to map the TPP back to a preclinical set of criteria that is required to uphold the “base case” in the clinical profile. Development candidate (DC) criteria (exemplary in Fig. 2) should be established to similarly set up threshold performance specifications for a program that are required to move it forward into IND-enabling studies and then subsequently into the clinic. Every time you receive a new piece of data, consider it in the context of the DC criteria and TPP – how does your estimation of the program stack up with this new data in mind? You may become more bullish that the profile is competitive and exceeding expectations, or you may decide that a certain limitation (e.g., narrow tox margins, lack of compatibility with oral dosing) make the profile untenable for a given indication.
Sam recommends framing up goals (annual, quarterly, and even per-experiment) based on the construct of “what would we like to be able to say about our program if it goes as well as we could imagine, and what will we have proven?” It’s important to lay out expectations for success ahead of a readout, to minimize bias that creeps in after we have seen data and know what is or is not feasible. You will undoubtedly encounter hurdles – experiments that are negative or challenging to interpret. But setting up expectations prospectively allows you and your team to rapidly pivot in a data-driven manner and while keeping the big-picture DC criteria and TPP in mind.
For a platform company, consider approaching every technological fork in the road with the question “does this serve my programs and target indications?” It may be difficult to draw the line between what is scientifically interesting for the platform (continual technological advancement and clever add-ons) vs. what is essential to drive execution towards the clinic for your program. Much like you map out a DC checklist and TPP, consider applying similar logic for each experiment testing your platform:
- What is this experiment testing?
- What does full success look like, and how does it enable my programs?
- If successful, what are the next 1-3 experiments?
- How does this readout enable progress towards the clinic for my programs?
It can be easy to revert to letting the data drive decisions, but in doing so we may stray away from the original goals and the therapeutic program in mind. For platform companies there are nearly infinite degrees of freedom, so there is a balance between what is “good enough” for version 1.0 that enables progress towards clinic and what is best saved for version 2.0+ once early de-risking is achieved.
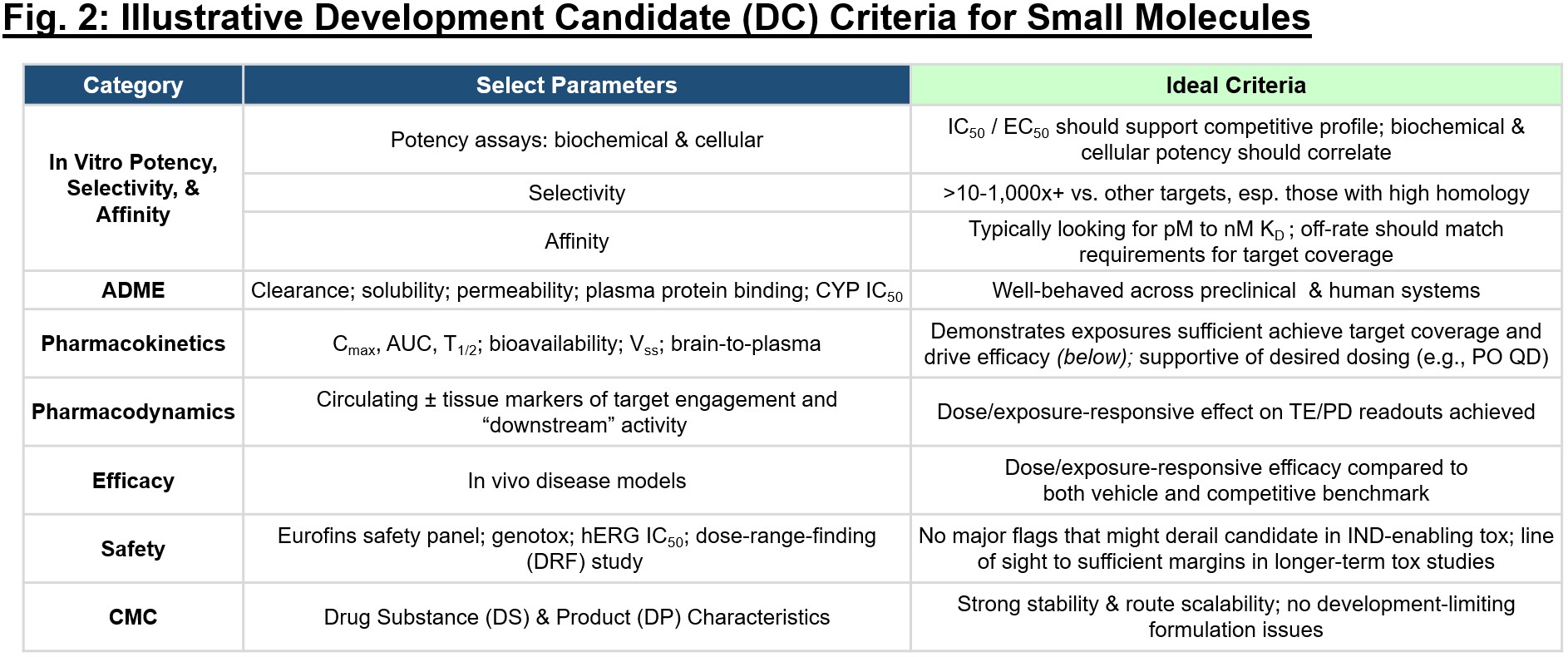
The DC criteria and TPP can serve as inputs to distinct but related decision frameworks that can be used to continuously evaluate preclinical or clinical readouts against a prospectively defined minimum viable profile (see Fig. 3). For each node in the decision tree, take time to map out expectations for critical readouts – what does the “go-forward” base case scenario include? A company’s strategy is ultimately influenced by these data, so consider implications for financing opportunities, strategic decisions (additional pipeline, indication expansion), and path to the clinic or eventual approval for the key readouts.
Of course, no one is suggesting a single experimental readout should be cause for shutting down a program or company. But what is the right criteria? As Alex puts it, it’s all about balancing curiosity and conviction with the probability of success, and that may look different for a given team, board, or company. History has taught us that in some instances (e.g., ALNY, TRIL, PCYC, LBPH), to give up early would have meant forgoing incredible advances for patients. But those examples are often exceptions to the rule, where relentless persistence has paid off. If you and your team have encountered experiment after experiment of gray data, or have tried to fundraise for more than a year unsuccessfully, or are at a collective loss as to how to progress a program, take a moment of pause. Does the data (internal or external) tell you something different about your program or platform than your ingoing assumption? If so, is there a path forward with a pivot, or is it time to reassess the path forward for this particular thesis?
Ultimately, remember that candor, objectivity, and proactivity are often helpful when murky data emerges. It’s helpful to ground everyone to the same base case so that when anything unexpected arises, stakeholders are best situated to evaluate it objectively and quickly determine the best path forward. Drug discovery and development is a team sport – teams and boards should collaboratively work together on all aspects of expectation-setting as well as analysis and decision once the data emerges.
Appreciate that our cumulative definition of “failure” should be re-framed:
Now that we’ve set up best practices for rigorously evaluating a program or platform’s profile, it’s important to acknowledge all the nuanced reasons why remaining objective is so difficult to do in real life. Setting up expectations and then missing the mark can be existential, Alex mentions, especially for a company focused on a single program or target. Additionally, there may be an asymmetric perception of risks for an operator compared to other stakeholders, where the former may have dedicated many years to this sole endeavor and feel a sense of loss aversion when faced with the potential of shutting it down.
All three of Alex, Sam, and Abbas have emphasized that the industry should consider how we define and speak about success vs. failure. Rigorously developing a hypothesis and approach to testing that hypothesis, regardless of the end result, should be applauded as a success. The only way we can push our understanding of science and medicine forward is to test these hypotheses and disseminate the readouts to the community. Where would the incretin field be if Novo hadn’t persevered in improving the half-life of GLP-1 analogs when original molecules stalled? If Roche hadn’t first failed to slow Alzheimer’s progression with gantenerumab and crenezumab, would they have had the insights to develop trontinemab, a next-gen TfR1 shuttle conjugated to anti-amyloid? Countless new programs are born out of hard-learned failures.
Additionally, it’s important to dissociate any ego or personal identity from the outcome of a well-planned experiment. Just because a program or technology fails to move forward doesn’t imply the people running the program failed. In fact, if they got to a “no-go” quickly, they made a huge contribution to their team’s and the collective industry’s knowledge for a given target or approach. Abbas recommends cheering for yourself and others when you decide to shut a program down just as much as when a program moves forward – ultimately our ecosystem is data-driven, and even negative data can help to advance knowledge and future medicines. At Nimbus, they have a saying: “like the program, love the portfolio.” To let go of one program where the thesis hasn’t panned out frees up bandwidth and resources to execute on programs that do. With this mentality in mind, over a representative time frame from 2016-2022, Nimbus shut down 70% of the programs it was working on for a variety of reasons: scientific, commercial, competitive positioning, etc. In acknowledging when a thesis wasn’t advancing, their team collectively re-deployed energy and talent to those programs that did, undoubtedly driving to the successful TYK2 program (now in the hands of Takeda), WRN inhibitor, and more.
It should be noted that success in “failing fast” is best enabled when company leadership, investors, boards, and other stakeholders are all aligned on the stated mission and expectation for “what good looks like.” This logic is best framed ahead of readouts and when companies have sufficient runway, as nothing breeds poor decisions like a limited runway and lack of backup options.
Every company and situation is unique, so there is no right or wrong answer on when to keep pushing vs. throw in the towel. Hopefully the frameworks here are useful the next time you find yourself staring down that question. Ultimately we each have a fixed amount of time to do some real good for patients – how will you decide to spend it?
Thank you to Sam Truex, Alex Harding, and Abbas Kazimi for generously sharing their perspectives and time for this article. Many thanks also to Akshay Vaishnaw for providing feedback on this post.